配置
config.py 文件使您能够根据自己的特定需求和偏好自定义 GPT Researcher。
感谢我们优秀的社区和贡献,GPT Researcher 支持多种大型语言模型(LLM)和检索器(Retriever)。此外,GPT Researcher 还可以根据各种报告格式(如 APA)、字数、研究迭代深度等进行定制。
GPT Researcher 默认使用我们推荐的集成套件:用于 LLM 调用的 OpenAI 和用于检索实时网络信息的 Tavily API。
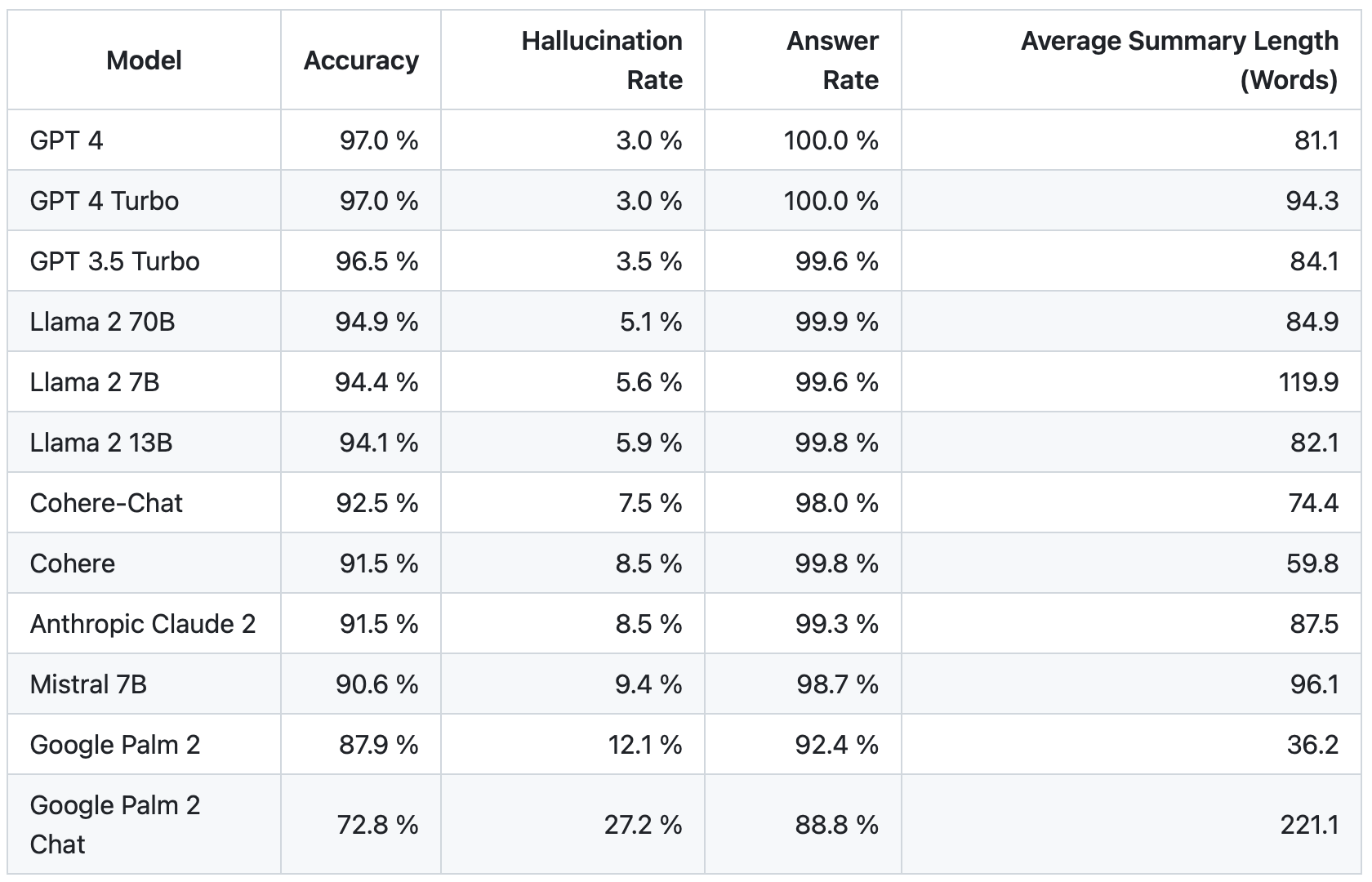
如下所示,OpenAI 仍然是卓越的 LLM。我们认为这种情况会持续一段时间,并且价格只会继续下降,而性能和速度会随着时间的推移而增加。
默认的 config.py 文件可以在 /gpt_researcher/config/ 中找到。它支持各种选项以根据您的需求定制 GPT Researcher。您还可以通过在 config_file 参数中添加路径来包含自己的外部 JSON 文件 config.json。请关注 config.py 文件以获取未来的更多支持。
以下是当前支持的选项列表
RETRIEVER:用于检索来源的网络搜索引擎。默认为tavily。选项:duckduckgo、bing、google、searchapi、serper、searx。在此处查看支持的检索器。EMBEDDING:嵌入模型。默认为openai:text-embedding-3-small。选项:ollama、huggingface、azure_openai、custom。SIMILARITY_THRESHOLD:处理文档时用于相似性比较的阈值。默认为0.42。FAST_LLM:用于快速 LLM 操作(如摘要)的模型名称。默认为openai:gpt-4o-mini。SMART_LLM:用于智能操作(如生成研究报告和推理)的模型名称。默认为openai:gpt-4.1。STRATEGIC_LLM:用于战略操作(如生成研究计划和策略)的模型名称。默认为openai:o4-mini。LANGUAGE:最终研究报告使用的语言。默认为english(英语)。CURATE_SOURCES:是否为研究筛选来源。此步骤会增加一次 LLM 运行,可能会增加成本和总运行时间,但能提高来源选择的质量。默认为False。FAST_TOKEN_LIMIT:快速 LLM 响应的最大令牌限制。默认为2000。SMART_TOKEN_LIMIT:智能 LLM 响应的最大令牌限制。默认为4000。STRATEGIC_TOKEN_LIMIT:战略 LLM 响应的最大令牌限制。默认为4000。BROWSE_CHUNK_MAX_LENGTH:在网络来源中浏览的文本块的最大长度。默认为8192。SUMMARY_TOKEN_LIMIT:生成摘要的最大令牌限制。默认为700。TEMPERATURE:LLM 响应的采样温度,通常在 0 到 1 之间。较高的值会产生更多的随机性和创造性,而较低的值会产生更专注和确定性的响应。默认为0.4。USER_AGENT:用于网络爬取和网络请求的自定义用户代理字符串。MAX_SEARCH_RESULTS_PER_QUERY:每次查询检索的最大搜索结果数。默认为5。MEMORY_BACKEND:用于内存操作的后端,例如临时数据的本地存储。默认为local。TOTAL_WORDS:用于文档生成或处理任务的总字数限制。默认为1200。REPORT_FORMAT:报告生成的首选格式。默认为APA。可以考虑如MLA、CMS、Harvard style、IEEE等格式。MAX_ITERATIONS:诸如查询扩展或搜索优化等过程的最大迭代次数。默认为3。AGENT_ROLE:代理的角色。此配置用于设置专门研究代理的行为。默认为None。设置后,它会激活针对特定研究领域的角色特定提示和技术。MAX_SUBTOPICS:要生成或考虑的最大子主题数。默认为3。SCRAPER:用于收集信息的网络爬虫。默认为bs(BeautifulSoup)。您也可以使用 newspaper。MAX_SCRAPER_WORKERS:每次研究的最大并发爬虫工作线程数。默认为15。REPORT_SOURCE:研究报告的数据来源。默认为web,用于在线研究。可以设置为doc,用于基于本地文档的研究。这决定了 GPT Researcher 从何处收集其主要信息。DOC_PATH:读取和研究本地文档的路径。默认为./my-docs。PROMPT_FAMILY:要使用的提示家族和提示格式。默认为针对 GPT 模型优化的提示。在 enum.py 中查看完整的选项列表。LLM_KWARGS:在实例化 LLM 提供程序类时要传递给它的额外关键字参数的 Json 格式字典。这对于像 Ollama 这样允许额外关键字参数(如影响推理调用的num_ctx)的客户端尤其有用。EMBEDDING_KWARGS:在实例化嵌入提供程序类时要传递给它的额外关键字参数的 Json 格式字典。DEEP_RESEARCH_BREADTH:控制深度研究的广度,定义要探索的并行路径数量。默认为3。DEEP_RESEARCH_DEPTH:控制深度研究的深度,定义要执行的顺序搜索次数。默认为2。DEEP_RESEARCH_CONCURRENCY:控制深度研究操作的并发级别。默认为4。REASONING_EFFORT:控制战略模型的推理力度。默认为medium。
深度研究配置
深度研究参数允许您微调 GPT Researcher 探索需要广泛知识收集的复杂主题的方式。这些参数共同决定了研究过程的彻底性和效率。
-
DEEP_RESEARCH_BREADTH:控制同时探索的并行研究路径数量。较高的值(例如 5)会使研究员在每一步调查更多样化的子主题,从而实现更广泛的覆盖,但可能对核心主题的关注度较低。默认值3在广度和深度之间提供了平衡的方法。 -
DEEP_RESEARCH_DEPTH:决定 GPT Researcher 为每个研究路径执行的顺序搜索迭代次数。较高的值(例如 3-4)允许跟踪引文并深入研究专业信息,但会大大增加研究时间。默认值2确保了合理的深度,同时保持了实际的完成时间。 -
DEEP_RESEARCH_CONCURRENCY:设置深度研究期间可以运行的并发操作数。较高的值可以加速在功能强大的系统上的研究过程,但可能会增加 API 速率限制问题或资源消耗。默认值4适用于大多数环境,但在资源更多的系统上可以增加,或者如果您遇到性能问题可以减少。
对于学术或高度专业化的研究,可以考虑增加广度和深度(例如,BREADTH=4, DEPTH=3)。对于快速的探索性研究,较低的值(例如,BREADTH=2, DEPTH=1)将提供更快的结果,但细节较少。
要更改默认配置,您可以简单地将环境变量添加到您的 .env 文件中,如上所述,或在您的本地项目目录中手动导出。
例如,要手动更改搜索引擎和报告格式
export RETRIEVER=bing
export REPORT_FORMAT=IEEE
请注意,您可能需要为其他受支持的搜索检索器和 LLM 提供程序导出额外的环境变量并获取 API 密钥。请关注您的控制台日志以获取进一步的帮助。要了解更多关于额外 LLM 支持的信息,您可以在这里查看文档。
您还可以通过在 config_file 参数中添加路径来包含您自己的外部 JSON 文件 config.json。