学习如何使用 LangGraph 和一支专业的 AI 代理团队来构建一个自主研究助理
GPT Researcher 初版发布至今仅一年,但构建、测试和部署 AI 代理的方法已经发生了显著演变。这正是当前 AI 发展速度和本质的体现。从简单的零样本或少样本提示开始,迅速演变为代理函数调用、RAG,现在最终演变为代理工作流(即“流程工程”)。
吴恩达(Andrew Ng)最近表示:“我认为 AI 代理工作流将在今年推动巨大的 AI 进步——甚至可能超过下一代基础模型。这是一个重要的趋势,我敦促所有从事 AI 工作的人都关注它。”
在本文中,您将学习为什么多智能体工作流是当前最佳标准,以及如何使用 LangGraph 构建最优的自主研究多智能体助理。
要跳过本教程,请随时查看 GPT Researcher x LangGraph 的 Github 仓库。
LangGraph 简介
LangGraph 是 LangChain 的一个扩展,旨在创建智能体和多智能体工作流。它增加了创建循环流程的能力,并内置了内存——这两者都是创建智能体的重要属性。
LangGraph 为开发者提供了高度的可控性,对于创建自定义代理和流程至关重要。生产环境中的几乎所有代理都是针对其试图解决的特定用例进行定制的。LangGraph 让你能够灵活地创建任意定制的代理,同时为此提供了直观的开发者体验。
闲话少说,让我们开始构建吧!
构建终极自主研究代理
通过利用 LangGraph,可以利用多个具有专业技能的代理来显著提高研究过程的深度和质量。让每个代理只专注于特定的技能,可以实现更好的关注点分离、可定制性,并随着项目的增长实现规模化的进一步发展。
受近期 STORM 论文的启发,这个例子展示了一个 AI 智能体团队如何协同工作,对给定主题进行研究,从规划到发布。这个例子还将利用领先的自主研究智能体 GPT Researcher。
研究智能体团队
研究团队由七个 LLM 智能体组成
- 总编辑 — 监督研究过程并管理团队。这是使用 LangGraph 协调其他智能体的“主”智能体。该智能体充当主要的 LangGraph 接口。
- GPT Researcher — 一个专业的自主智能体,对给定主题进行深入研究。
- 编辑 — 负责规划研究大纲和结构。
- 审阅者 — 根据一组标准验证研究结果的正确性。
- 修订者 — 根据审阅者的反馈修订研究结果。
- 作者 — 负责整理和撰写最终报告。
- 发布者 — 负责以各种格式发布最终报告。
如下图所示,自动化过程基于以下几个阶段:规划研究、数据收集与分析、审阅与修订、撰写报告以及最终发布
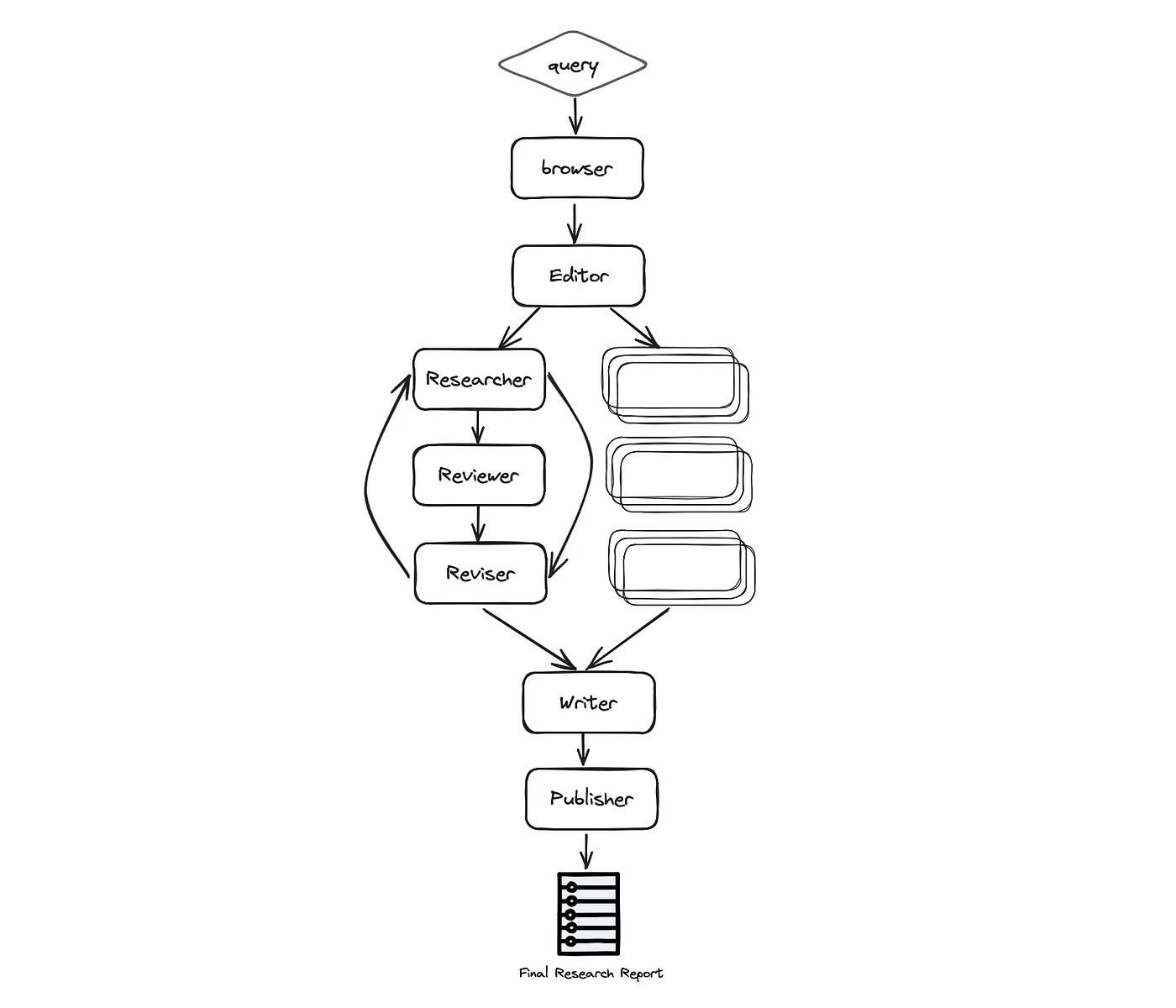
更具体地说,过程如下
-
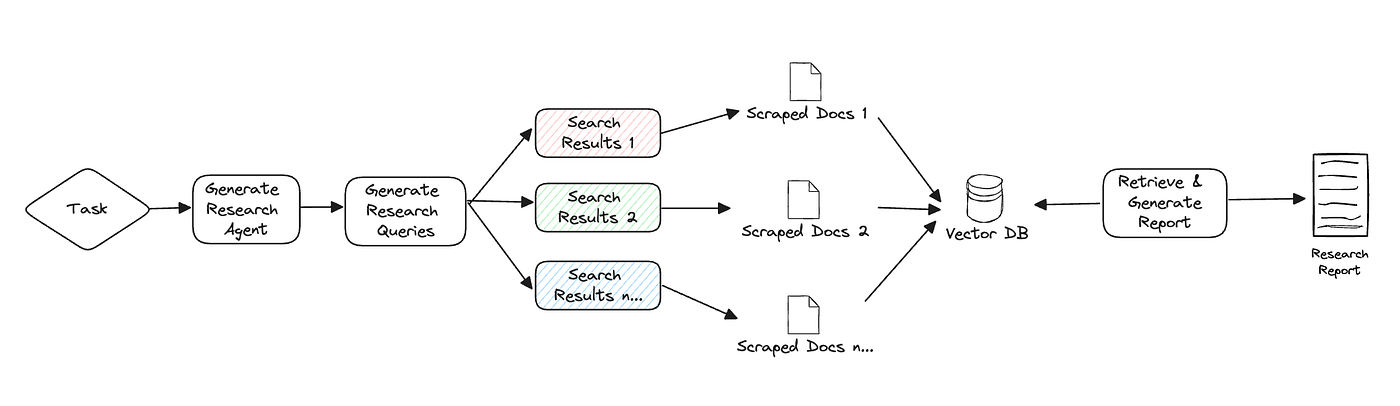
浏览器 (gpt-researcher) — 根据给定的研究任务,在互联网上进行初步研究。这一步对于大语言模型(LLM)根据最新和相关信息规划研究过程至关重要,而不是仅仅依赖于针对特定任务或主题的预训练数据。
-
编辑 — 根据初步研究规划报告大纲和结构。编辑还负责根据规划的大纲触发并行的研究任务。
-
针对每个大纲主题(并行进行)
- 研究员(gpt-researcher) — 对子主题进行深入研究并撰写草稿。该智能体在底层利用 GPT Researcher Python 包,以获得优化、深入且基于事实的研究报告。
- 审阅者 — 根据一套准则验证草稿的正确性,并向修订者提供反馈(如果有)。
- 修订者 — 根据审阅者的反馈修订草稿,直到满意为止。
-
作者 — 根据给定的研究发现,整理并撰写最终报告,包括引言、结论和参考文献部分。
-
发布者 — 将最终报告发布为多种格式,如 PDF、Docx、Markdown 等。
-
我们不会深入探讨所有代码,因为代码量很大,但会主要关注我发现有价值分享的有趣部分。
定义图状态
LangGraph 中我最喜欢的功能之一是状态管理。LangGraph 中的状态是通过一种结构化的方法来管理的,开发者定义一个 `GraphState` 来封装应用程序的整个状态。图中的每个节点都可以修改这个状态,从而可以根据交互的演变上下文做出动态响应。
就像任何技术设计的开端一样,考虑整个应用程序的数据模式是关键。在这种情况下,我们将定义一个 `ResearchState`,如下所示
class ResearchState(TypedDict):
task: dict
initial_research: str
sections: List[str]
research_data: List[dict]
title: str
headers: dict
date: str
table_of_contents: str
introduction: str
conclusion: str
sources: List[str]
report: str
如上所示,状态分为两个主要领域:研究任务和报告布局内容。当数据在图代理之间流转时,每个代理会依次根据现有状态生成新数据,并为图下游的其他代理进行后续处理而更新它。
然后我们可以用以下方式初始化图
from langgraph.graph import StateGraph
workflow = StateGraph(ResearchState)
用 LangGraph 初始化图。如上所述,多智能体开发的一大优点是构建每个智能体,使其具有专业化和范围明确的技能。让我们以使用 GPT Researcher python 包的 Researcher 智能体为例
from gpt_researcher import GPTResearcher
class ResearchAgent:
def __init__(self):
pass
async def research(self, query: str):
researcher = GPTResearcher(parent_query=parent_query, query=query, report_type=research_report, config_path=None)
await researcher.conduct_research()
report = await researcher.write_report()
return report
如上所示,我们已经创建了一个 Research 智能体的实例。现在让我们假设我们已经为团队中的每个智能体都做了同样的操作。在创建所有智能体之后,我们将用 LangGraph 初始化图
def init_research_team(self):
editor_agent = EditorAgent(self.task)
research_agent = ResearchAgent()
writer_agent = WriterAgent()
publisher_agent = PublisherAgent(self.output_dir)
workflow = StateGraph(ResearchState)
workflow.add_node("browser", research_agent.run_initial_research)
workflow.add_node("planner", editor_agent.plan_research)
workflow.add_node("researcher", editor_agent.run_parallel_research)
workflow.add_node("writer", writer_agent.run)
workflow.add_node("publisher", publisher_agent.run)
workflow.add_edge('browser', 'planner')
workflow.add_edge('planner', 'researcher')
workflow.add_edge('researcher', 'writer')
workflow.add_edge('writer', 'publisher')
workflow.set_entry_point("browser")
workflow.add_edge('publisher', END)
return workflow
如上所示,创建 LangGraph 图非常直接,由三个主要函数组成:add_node、add_edge 和 set_entry_point。通过这些主要函数,您可以首先将节点添加到图中,连接边,最后设置起点。
注意检查:如果你一直正确地跟随代码和架构,你会注意到审阅者(Reviewer)和修订者(Reviser)智能体在上面的初始化中缺失了。让我们深入探讨一下!
图中之图,以支持有状态的并行化
这是我使用 LangGraph 过程中最激动人心的部分!这个自主助理的一个令人兴奋的特性是为每个研究任务进行并行运行,这些任务会根据一组预定义的准则进行审阅和修订。
了解如何在一个流程中利用并行工作是优化速度的关键。但是,如果所有代理都向同一个状态报告,你将如何触发并行代理工作呢?这可能导致竞态条件和最终数据报告中的不一致。为了解决这个问题,你可以创建一个子图,这个子图会由主 LangGraph 实例触发。这个子图会为每个并行运行保持自己的状态,从而解决所提出的问题。
和之前一样,让我们定义 LangGraph 的状态和它的智能体。由于这个子图基本上是审阅和修订一份研究草稿,我们将用草稿信息来定义状态
class DraftState(TypedDict):
task: dict
topic: str
draft: dict
review: str
revision_notes: str
如 DraftState 中所示,我们主要关心讨论的主题,以及审阅者和修订说明,因为它们在彼此之间沟通以最终确定子主题研究报告。为了创建循环条件,我们将利用 LangGraph 的最后一个重要部分,即条件边。
async def run_parallel_research(self, research_state: dict):
workflow = StateGraph(DraftState)
workflow.add_node("researcher", research_agent.run_depth_research)
workflow.add_node("reviewer", reviewer_agent.run)
workflow.add_node("reviser", reviser_agent.run)
workflow.set_entry_point("researcher")
workflow.add_edge('researcher', 'reviewer')
workflow.add_edge('reviser', 'reviewer')
workflow.add_conditional_edges('reviewer',
(lambda draft: "accept" if draft['review'] is None else "revise"),
{"accept": END, "revise": "reviser"})
通过定义条件边,如果审阅者有审阅说明,图将指向修订者,否则循环将以最终草案结束。如果你回到我们构建的主图,你会看到这个并行工作在一个名为“researcher”的节点下,由 ChiefEditor 代理调用。
运行研究助理 在最终确定智能体、状态和图之后,是时候运行我们的研究助理了!为了使其更易于定制,该助理通过一个给定的 `task.json` 文件运行
{
"query": "Is AI in a hype cycle?",
"max_sections": 3,
"publish_formats": {
"markdown": true,
"pdf": true,
"docx": true
},
"follow_guidelines": false,
"model": "gpt-4-turbo",
"guidelines": [
"The report MUST be written in APA format",
"Each sub section MUST include supporting sources using hyperlinks. If none exist, erase the sub section or rewrite it to be a part of the previous section",
"The report MUST be written in spanish"
]
}
任务对象非常不言自明,但请注意,如果 `follow_guidelines` 为 false,则会导致图忽略修订步骤和定义的指导方针。此外,`max_sections` 字段定义了要研究多少个子标题。设置得少一些会生成更短的报告。
运行该助手将生成一份最终的研究报告,格式包括 Markdown、PDF 和 Docx。
要下载并运行该示例,请查看 GPT Researcher x LangGraph 的开源页面。
下一步是什么?
展望未来,有一些非常令人兴奋的事情值得思考。人在回路(Human in the loop)是优化 AI 体验的关键。让人类帮助助理修订并专注于正确的研究计划、主题和提纲,将提高整体质量和体验。总的来说,在整个 AI 流程中依赖人类干预,可以确保正确性、控制感和确定性结果。很高兴看到 LangGraph 已经开箱即用地支持这一点,如此处所示。
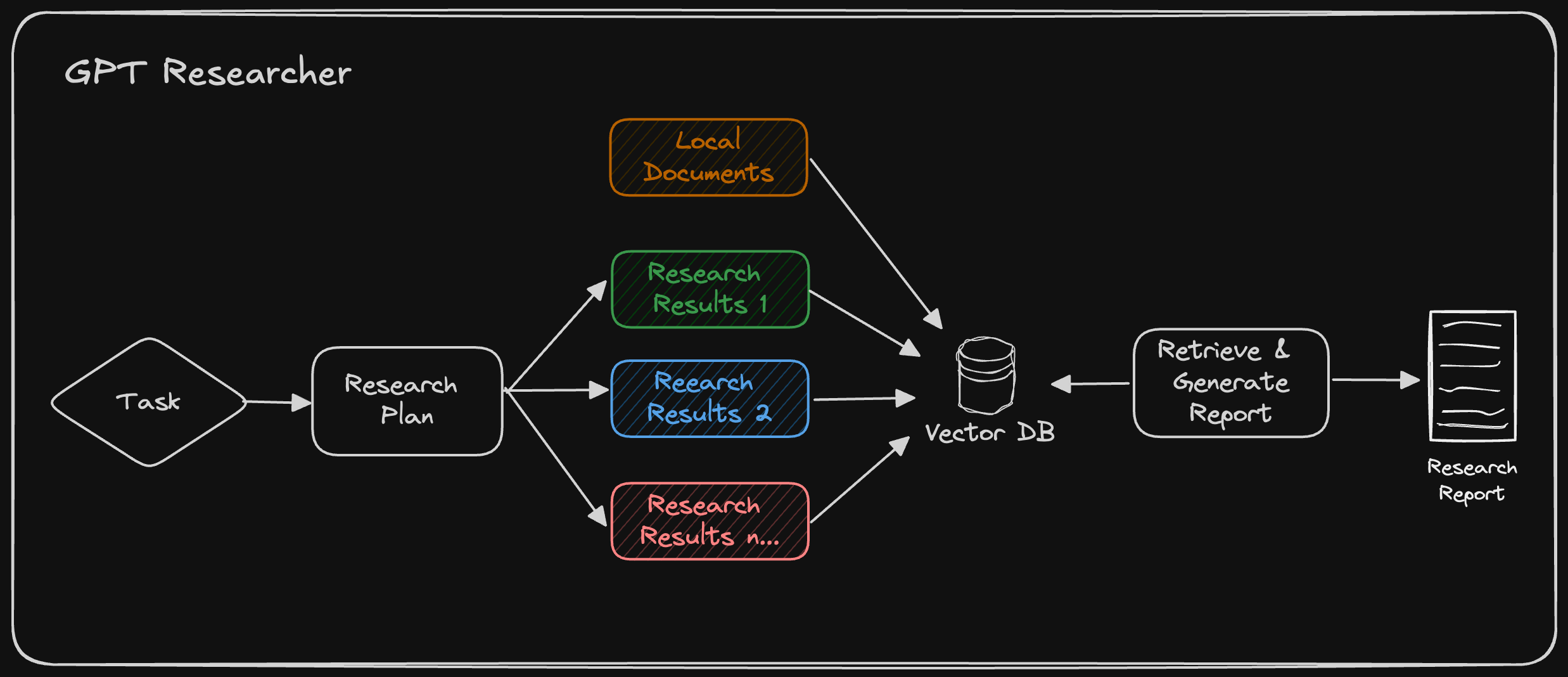
此外,支持对网络和本地数据的研究对于许多商业和个人用例来说将是关键。
最后,可以做出更多努力来提高检索到来源的质量,并确保最终报告以最佳的故事情节构建。
LangGraph 和多代理协作的下一步发展将是,助理可以根据给定的任务动态地规划和生成图。这一愿景将允许助理为特定任务只选择一部分代理,并根据本文中介绍的图基本原理来规划其策略,从而开启一个全新的可能性世界。鉴于 AI 领域的创新速度,不久就会推出一个颠覆性的新版 GPT Researcher。期待未来带来的一切!
要持续关注该项目的进展和更新,请加入我们的 Discord 社区。和往常一样,如果您有任何反馈或进一步的问题,请在下方评论!