研究的未来是混合模式


在过去的几年里,我们见证了旨在颠覆研究领域的新型人工智能工具的爆炸式增长。其中一些工具,如 ChatPDF 和 Consensus,专注于从文档中提取见解。另一些工具,如 Perplexity,则擅长在网络上搜索信息。但问题是:这些工具中没有一个能将网络搜索和本地文档搜索结合在单一的、有上下文的研究流程中。
这就是为什么我很高兴能向大家介绍 GPT Researcher 的最新进展——现在它能够针对任何给定的任务和文档进行混合研究。
由网络驱动的研究通常缺乏特定背景,存在信息过载的风险,并且可能包含过时或不可靠的数据。另一方面,由本地驱动的研究仅限于历史数据和现有知识,可能造成组织内部的回声室效应,并错过关键的市场趋势或竞争对手的动态。这两种方法如果孤立使用,都可能导致不完整或有偏见的见解,从而妨碍您做出充分知情的决策。
今天,我们将改变这一局面。在本指南的最后,您将学会如何进行混合研究,它结合了网络和本地两种方式的优点,使您能够进行更彻底、更相关、更有见地的研究。
为什么混合研究效果更好
通过结合网络和本地来源,混合研究解决了这些局限性,并提供了几个关键优势:
-
有根据的背景:本地文档为研究提供了经过验证的、特定于组织的信息基础。这使研究植根于已有的知识,降低了偏离核心概念或误解行业特定术语的风险。
示例:一家制药公司在研究新药开发机会时,可以将其内部研究论文和临床试验数据作为基础,然后用网上最新发表的研究和监管更新来补充。
-
提高准确性:网络来源提供最新信息,而本地文档提供历史背景。这种结合可以进行更准确的趋势分析和决策。
示例:一家金融服务公司在分析市场趋势时,可以将其历史交易数据与实时市场新闻和社交媒体情绪分析相结合,从而做出更明智的投资决策。
-
减少偏见:通过同时从网络和本地来源获取信息,我们降低了任何单一来源中可能存在的偏见风险。
示例:一家科技公司在评估其产品路线图时,可以将内部功能请求和使用数据与外部客户评论和竞争对手分析相平衡,确保获得全面的视角。
-
改进规划和推理:大语言模型(LLM)可以利用本地文档的背景信息,更好地规划其网络研究策略,并对在网上找到的信息进行推理。
示例:一个由人工智能驱动的市场研究工具,可以利用公司过去的市场活动数据来指导其在网上搜索当前的市场趋势,从而获得更相关、更具可操作性的见解。
-
定制化见解:混合研究允许将专有信息与公共数据相结合,从而产生独特的、特定于组织的见解。
示例:一家零售连锁店可以将其销售数据与网络抓取的竞争对手定价和经济指标相结合,以优化其在不同地区的定价策略。
这些只是可以利用混合研究的商业用例中的几个例子,但闲话少说——让我们开始构建吧!
构建混合研究助手
在我们深入细节之前,值得一提的是,GPT Researcher 本身就具备进行混合研究的能力!然而,为了真正理解其工作原理并让您更深入地了解这个过程,我们将一探其究竟。
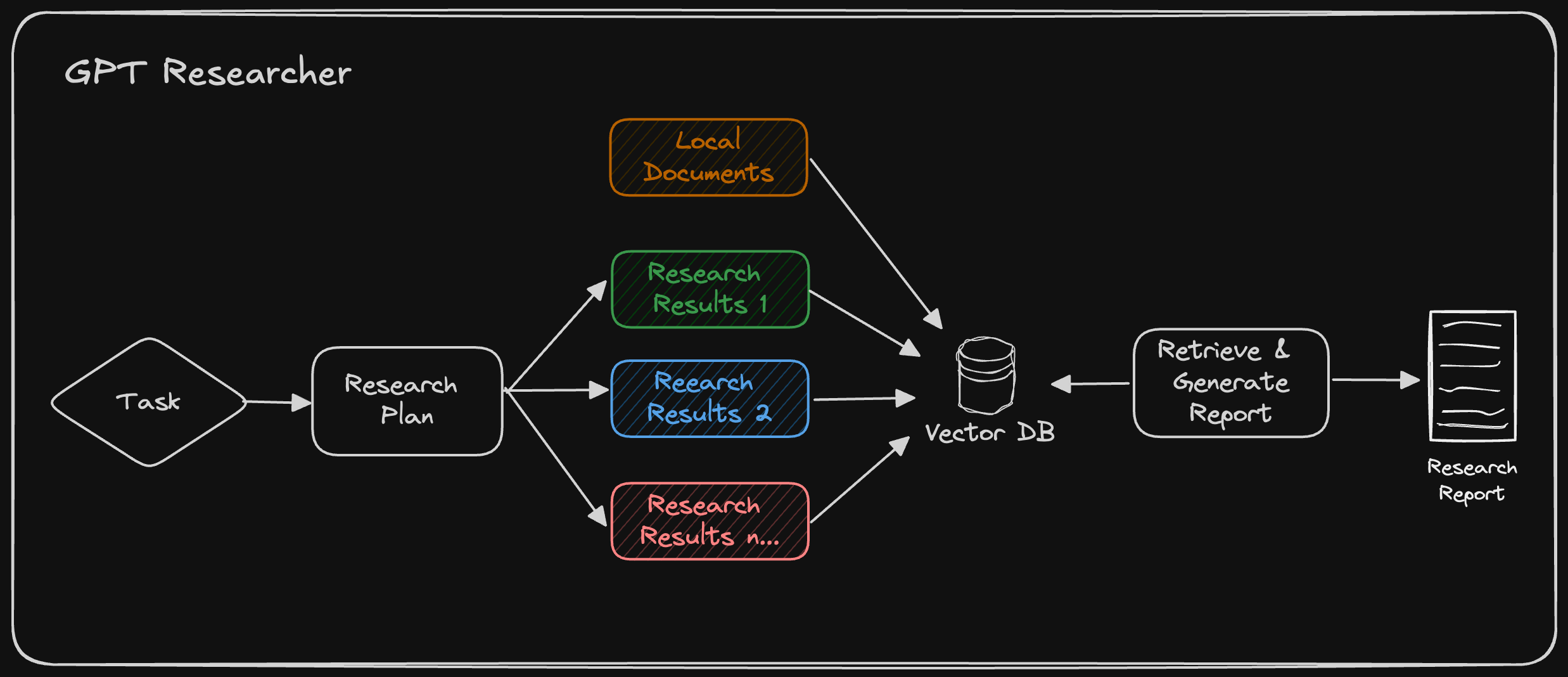
如上图所示,GPT Researcher 根据本地文档自动生成的计划进行网络研究。然后,它从本地和网络数据中检索相关信息,用于最终的研究报告。
我们将探讨如何使用 LangChain 处理本地文档,这是 GPT Researcher 文档处理的关键组成部分。然后,我们将向您展示如何利用 GPT Researcher 进行混合研究,将网络搜索的优势与您的本地文档知识库相结合。
使用 Langchain 处理本地文档
LangChain 提供了多种文档加载器,使我们能够处理不同的文件类型。在处理多样化的本地文档时,这种灵活性至关重要。以下是如何进行设置:
from langchain_community.document_loaders import (
PyMuPDFLoader,
TextLoader,
UnstructuredCSVLoader,
UnstructuredExcelLoader,
UnstructuredMarkdownLoader,
UnstructuredPowerPointLoader,
UnstructuredWordDocumentLoader
)
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
def load_local_documents(file_paths):
documents = []
for file_path in file_paths:
if file_path.endswith('.pdf'):
loader = PyMuPDFLoader(file_path)
elif file_path.endswith('.txt'):
loader = TextLoader(file_path)
elif file_path.endswith('.csv'):
loader = UnstructuredCSVLoader(file_path)
elif file_path.endswith('.xlsx'):
loader = UnstructuredExcelLoader(file_path)
elif file_path.endswith('.md'):
loader = UnstructuredMarkdownLoader(file_path)
elif file_path.endswith('.pptx'):
loader = UnstructuredPowerPointLoader(file_path)
elif file_path.endswith('.docx'):
loader = UnstructuredWordDocumentLoader(file_path)
else:
raise ValueError(f"Unsupported file type: {file_path}")
documents.extend(loader.load())
return documents
# Use the function to load your local documents
local_docs = load_local_documents(['company_report.pdf', 'meeting_notes.docx', 'data.csv'])
# Split the documents into smaller chunks for more efficient processing
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(local_docs)
# Create embeddings and store them in a vector database for quick retrieval
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
# Example of how to perform a similarity search
query = "What were the key points from our last strategy meeting?"
relevant_docs = vectorstore.similarity_search(query, k=3)
for doc in relevant_docs:
print(doc.page_content)
使用 GPT Researcher 进行网络研究
现在我们已经学会了如何处理本地文档,让我们快速了解一下 GPT Researcher 的工作原理:
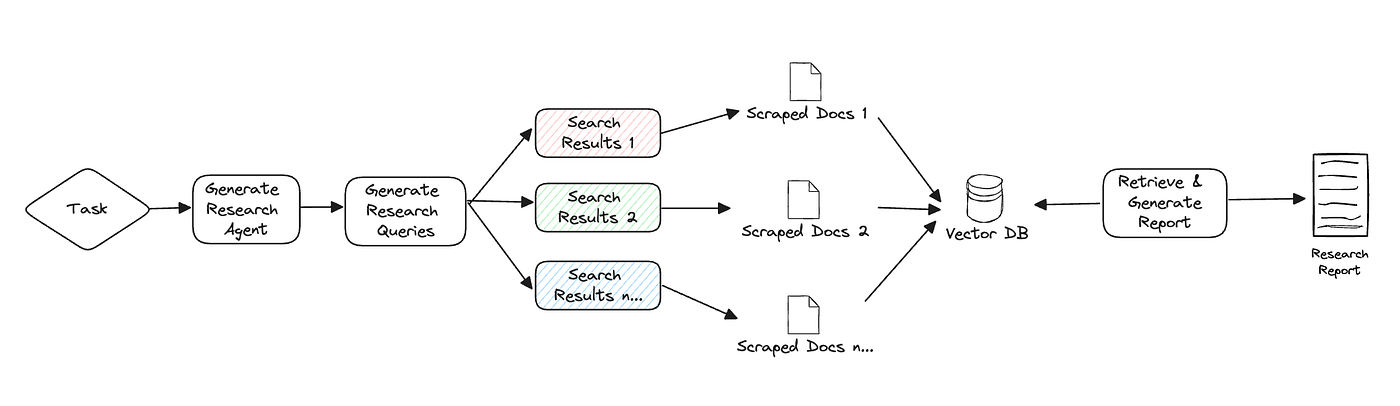
如上所示,GPT Researcher 根据给定的任务创建一个研究计划,通过生成潜在的研究查询,这些查询可以共同提供对该主题的客观而广泛的概述。一旦这些查询生成,GPT Researcher 就会使用像 Tavily 这样的搜索引擎来查找相关结果。每个抓取的结果都会被保存在一个向量数据库中。最后,检索与研究任务最相关的 k 个数据块,以生成最终的研究报告。
GPT Researcher 支持混合研究,这涉及一个额外的步骤,即在检索最相关的信息之前对本地文档进行分块(使用 Langchain 实现)。经过社区的大量评估,我们发现混合研究将最终结果的正确性提高了 40% 以上!
使用 GPT Researcher 运行混合研究
现在您对混合研究的工作原理有了更好的理解,让我们来演示一下使用 GPT Researcher 实现这一点是多么容易。
第一步:使用 PIP 安装 GPT Researcher
pip install gpt-researcher
第二步:设置环境
我们将使用 OpenAI 作为大语言模型(LLM)供应商,Tavily 作为搜索引擎来运行 GPT Researcher。在继续之前,您需要获取这两者的 API 密钥。然后,在您的命令行界面(CLI)中按如下方式导出环境变量:
export OPENAI_API_KEY={your-openai-key}
export TAVILY_API_KEY={your-tavily-key}
第三步:使用混合研究配置初始化 GPT Researcher
GPT Researcher 可以通过参数轻松初始化,以指示其运行混合研究。您可以进行多种形式的研究,请前往文档页面了解更多信息。
要让 GPT Researcher 运行混合研究,您需要将所有相关文件放在 my-docs 目录中(如果不存在,请创建它),并将实例的 report_source 设置为 "hybrid",如下所示。一旦报告源设置为 hybrid,GPT Researcher 将在 my-docs 目录中查找现有文档并将其包含在研究中。如果不存在任何文档,它将忽略此设置。
from gpt_researcher import GPTResearcher
import asyncio
async def get_research_report(query: str, report_type: str, report_source: str) -> str:
researcher = GPTResearcher(query=query, report_type=report_type, report_source=report_source)
research = await researcher.conduct_research()
report = await researcher.write_report()
return report
if __name__ == "__main__":
query = "How does our product roadmap compare to emerging market trends in our industry?"
report_source = "hybrid"
report = asyncio.run(get_research_report(query=query, report_type="research_report", report_source=report_source))
print(report)
如上所示,我们可以对以下示例进行研究:
- 研究任务:“我们的产品路线图与我们行业的新兴市场趋势相比如何?”
- 网络:当前市场趋势、竞争对手公告和行业预测
- 本地:内部产品路线图文件和功能优先级列表
经过多次社区评估,我们发现这项研究的结果将研究质量和正确性提高了 40% 以上,并将幻觉减少了 50%。此外,如上所述,本地信息有助于大语言模型改进规划和推理,使其能够做出更好的决策并研究更相关的网络来源。
但等等,还有更多!GPT Researcher 还包括一个使用 NextJS 和 Tailwind 构建的精美前端应用程序。要了解如何运行它,请查看文档页面。您可以轻松地使用拖放功能来处理文档,以进行混合研究。
结论
混合研究代表了数据收集和决策制定方面的一大进步。通过利用 GPT Researcher 等工具,团队现在可以进行更全面、更具上下文感知和更具可操作性的研究。这种方法解决了孤立使用网络或本地来源的局限性,带来了诸多好处,例如有根据的背景、更高的准确性、更少的偏见、改进的规划和推理能力以及定制化的见解。
混合研究的自动化可以使团队能够更快、更数据驱动地做出决策,最终提高生产力,并在分析不断扩大的非结构化和动态信息池方面提供竞争优势。